
Learn Machine Learning with Graph in Hyperconnected Data (Part 2.)
Following our previous article on Hyperconnected data, this article will delve deeper into the applications of graph-based machine learning specifically in the realm of e-commerce data. We will explore the practical implementation of unsupervised learning-based 'Graph Clustering' and supervised learning-based 'Graph node/Link Prediction' techniques, highlighting their significance in storing and harnessing results within a graph database. By understanding these powerful approaches, we can uncover valuable insights and optimize decision-making processes in the dynamic world of e-commerce.
Graph Projection and Clustering Analysis
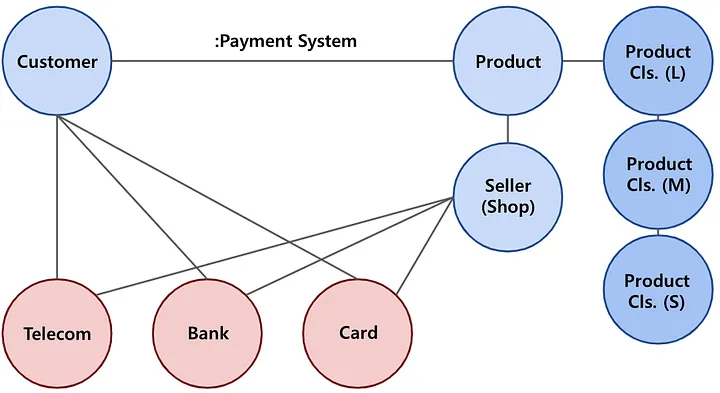
Once we understand the intricate product-purchase relationships within our e-commerce data, the next step is to cluster customers based on their shared properties. To accomplish this, we employ the 'Graph Projection' technique, which constructs a unified network by projecting a graph along specific relationships. By utilizing this approach, we can effectively visualize and analyze distinct customer clusters, uncovering valuable insights that can drive personalized marketing strategies and enhance overall customer experience.
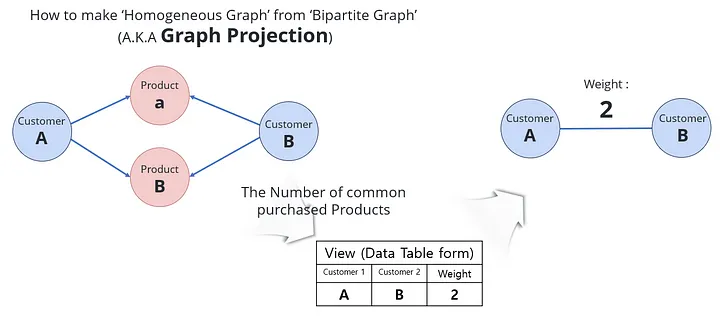
The relationship between Customer A and Customer B, connected through the purchase relationships of the same product, creates a view that facilitates a seamless connection between preceding relationships. This view acts as an edge, linking the edges of the graph projection.
Querying the Single Relationships
First, we can ask simple questions to find out what products customers buy and what services they use.
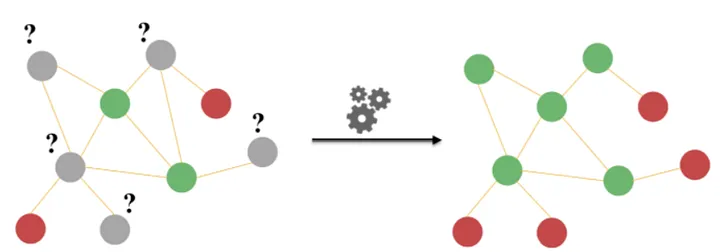
Essentially, we can construct a network comprising customers who have purchased the same product. From this network, we can employ a graph clustering algorithm to group customers based on structural similarities within the graph. The graph clustering algorithm analyzes the graph's structural features independently, allowing for the identification of distinctive characteristics within each cluster. Below is an example of a single network configuration and its characteristics when using the clustering algorithm, visualized as a graph.
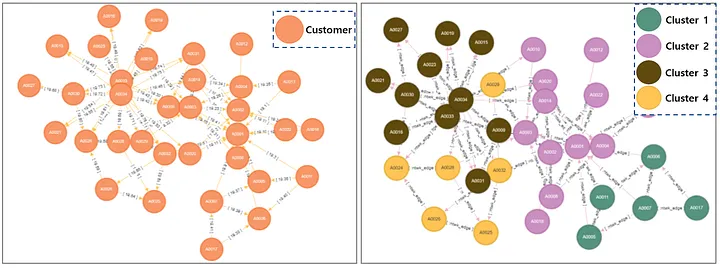
Querying Features of Clusters
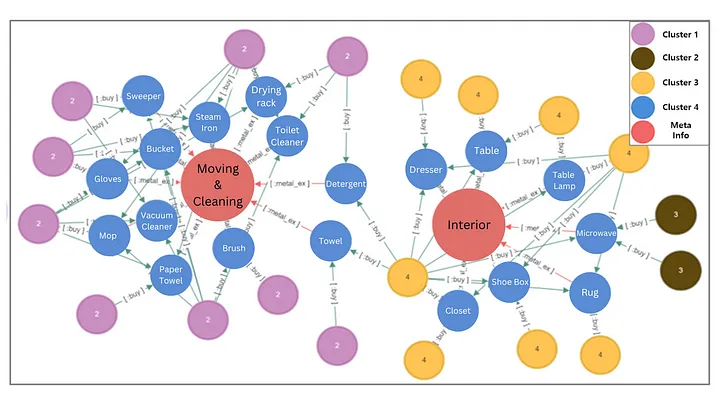
Focusing on products emerges a single network, revealing distinctive characteristics specific to each cluster. This network offers valuable insights and provides personalized recommendations to assist customers in finding what they truly need. Moreover, the configuration of this network unveils new meta-information beyond traditional categorization. Uncovering patterns of products purchased together suggests previously unseen characteristics of products, allowing for a deeper understanding of customer preferences and facilitating more targeted recommendations.
Node/Link Prediction
The results above demonstrate the meaningfulness of item purchases within the identified clusters. For instance, in Cluster 2, the purchase of cleaning supplies is appropriately grouped with the keyword 'Moving and Cleaning', enabling targeted product recommendations to customers in this cluster. Similarly, in Cluster 4, the purchases of furniture supplies are accurately associated with the keyword 'Interior,' allowing for precise suggestions to enhance customers interior design needs. These cluster-specific associations highlight the power of leveraging customer behavior data to provide relevant and contextually appropriate recommendations, ultimately improving the overall customer experience.
Beyond the established product categories, grouping, giving meta-information, and managing products relevant to the current era are also of the AGE's capability. These can be achieved utilizing Node/Link Prediction techniques, which enable the prediction and establishment of connections for items that have not yet been categorized or linked. By leveraging this approach, we can offer tailored recommendations that suggest customers with customer's genuine needs.
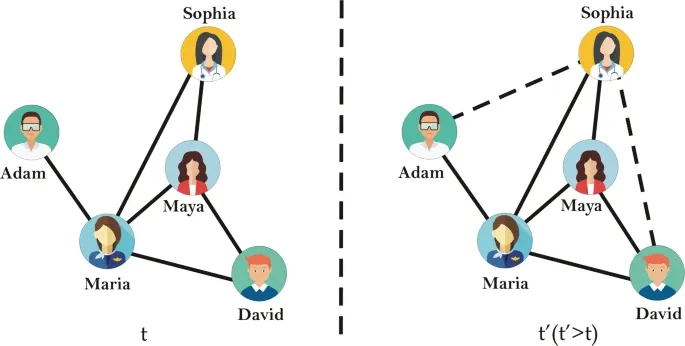
Node prediction operates at the individual node level within the graph, allowing for accurate predictions regarding the characteristics of a given node. This prediction is analyzed based on the relationships with irregular neighbouring nodes.
Link Prediction is a technique to predict the likelihood of a connection between two individual nodes without existing connections. By successfully establishing these previously unexplored relationships, the utility of information within the network significantly enhances.
In addition to traditional recommendation systems that rely on similarity-based approaches, Link prediction, when combined with Node prediction, facilitates recommendations based on similarities and discovers valuable information about the characteristics of newly defined nodes. This expanded data discovery opens up new avenues for exploration and analysis, ultimately boosting confidence in the generated results.
This article explored the concept of graph hyper-connection, the connection of table data from a relational database to a graph structure. By harnessing the power of hyperconnectivity between relational and graph databases, data can be managed flexibly, leading to the creation of new value through not only simple queries but also advanced analytics.
To efficiently model and manage different types of data, an enterprise DBMS like AGEDB is an ideal solution. It enables the identification and management of relationships between data in tables, facilitating the extension of knowledge associations and enabling comprehensive analysis through graph-based approaches.
AGEDB offers a powerful combination of a relational database and a graph extension, Apache AGE. Both products are built on the robust PostgreSQL foundation, enabling users to leverage additional extension modules and features. By integrating relational and graph databases, AGEDB facilitates hyper-connectivity not only in E-commerce but across various industries. Apache AGE is also compatible with SQL queries, eliminating the need for users to be proficient in graph-specific query languages. This versatility expands the applicability of AGEDB beyond graph queries. The strategic utilization of both databases fosters more efficient connections between people, objects, and other elements, transcending boundaries. This seamless integration empowers businesses to gain comprehensive insights, understand data flows, and create value across diverse domains.
Want to use both relational and graph databases? AGEDB is your solution to enable hyper-connectivity. Unlock valuable insights, enhance data exploration, and drive informed decision-making now with AGEDB !
Learn more from our experts at info@agedb.io!