
The Technology Behind You Need to Know in 2023.
It's only these past years since we started to hear 'Chat GPT,' 'AI-generated imgs,' 'AIs taking over our jobs!' etc. Why is this technology drawing all attention all this sudden? It's due in part because of its impacts on computing. This article will unravel the technology behind AI-generated imgs, providing valuable insights into the advancements, techniques, and applications that make them an indispensable part of our digital future.
How do AIs generate imgs?
The Stable Diffusion Model is a generative AI model that generates imgs to match text. This model helps create a detailed img according to the text input. It can also recreate a specific part of an existing img. Let's break things down.
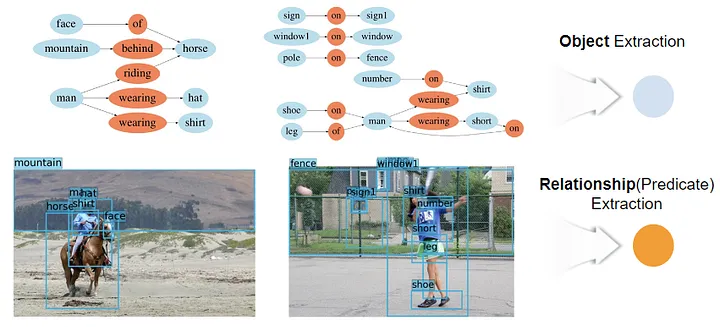
What is Scene Graph?
Scene Graph is a method of detecting objects in an img or video, then inferring the relationship between objects by making a graph. Figure 1. shows that an object from the img (Eg. Mountain and a horse) is extracted as a noun and expressed as a node in the graph, and the relationship between objects (Eg. behind) is extracted as a predicate to form a heterogeneous node and edge of the graph.
The graph expression method is in the limelight as it visually expresses a complex relationship between objects and makes inferences within imgs, unlike the existing 'img captioning' method. Scene Graph enables the creation of more accurate and specific imgs with a Stable Diffusion by structuring text prompts. Complex text prompts sometimes confuse the generative AI when the img generation model learns natural language. That is why specifying the relationship between words in these complex sentences through Scene Graph can create more diverse imgs clearer. In addition, the created imgs can also be easily modified by controlling specific words and relationships in Scene Graph.
So how do texts turn into imgs?
Methods for generating imgs by turning text prompts into Scene Graphs include 'Frido,' 'SceneGenie,' 'SGDiff,' 'SG2Im,' and 'diffuscene'. Among these, Scene Genie is a representative algorithm that uses a Stable Diffusion Model and has a high accuracy of generated imgs. Let's look at an algorithm that converts text prompts into Scene Graphs through this algorithm.
Stable Diffusion Model Process
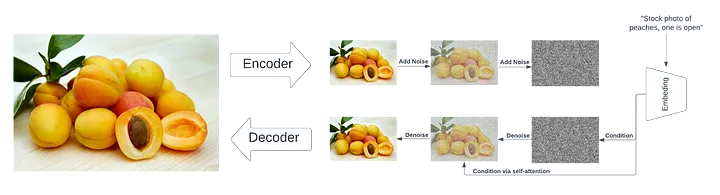
The Stable Diffusion Model uses Open AI's 'Contrastive Language-img' Pre-training (CLIP) model. CLIP is a huge pre-learning model with text and corresponding img information and provides latent information by mapping imgs suitable for text. After mapping texts into imgry, the img will go through the noising and denoising process. Denoising refers to restoring an img from noise. Noising, on the other hand, is the process of adding noise to an img. The repetition of this Noising and Denoising process leads to AI learning; The process lets the AI train itself multiple times by adding noise and restoring them to a given img to improve its capabilities in identifying and predicting the noise. (See Figure 2.) The Variational Autoencoder (VAE) is also a crucial step in img generation. VAE encodes and decodes imgs, and supports img optimization by speeding up the process.
Scene Genie - Stable Diffusion using Scene Graph
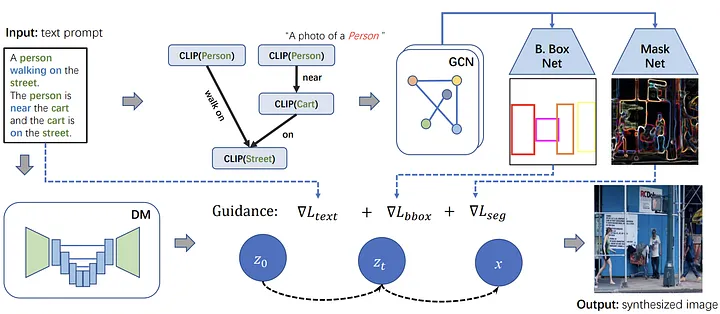
The simple text-to-img Stable Diffusion Model does not produce accurate imgs from complex text prompts. In particular, when many objects perform many actions with various relationships, it often leads to inaccurate img creation. SceneGenie, however, on top of its capabilities with simple text prompts, also predicts the approximate location area for imgs created using the Scene Graph that shows the relationship between objects.
In the existing Stable Diffusion Model, only imgs of latent information from CLIP learn to restore and generate through noise and denoise. In SceneGenie, Graph Convolution Network (GCN) trains the classification process and allows the latent information and the area of the object to b created as a Scene Graph. Therefore, the information collected and optimized makes it possible to clearly create imgs with more objects and relationships than existing generative models can.
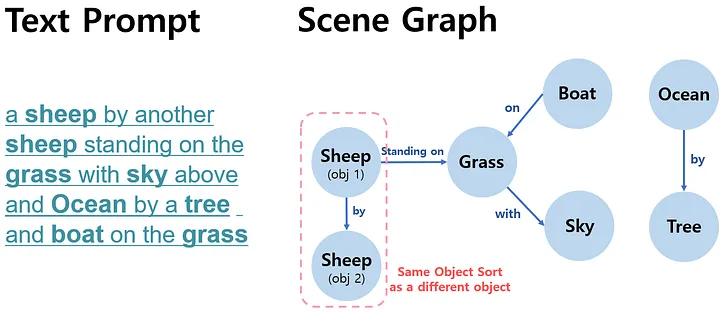

In the example above, you can see that SceneGenie, which uses the Scene Graph generated better imgs for complex objects and relationships. In the img generated by DALL.E 2, the word 'sheep' was recognized as one object. Scene Graph, however, classified 'sheep' mentioned twice in the text prompt as two different objects. Furthermore, other objects such as 'Boat' are also more accurately positioned as requested.
In essence, img generation using Scene Graphs creates more accurate imgs by decoding the relationships among complex objects. Existing img-generating AI is often difficult to generate a desired img with complex text prompts, especially when multiple objects are present. A Scene Graph expresses relationships between objects as a graph, making it easier to infer the situation within an img or text. With the progressive rise of generative AI, the adaption of Scene Graphs is becoming increasingly essential to achieving accurate and meaningful synthesis.
Scene Graph and Graph Technology still feel too advanced of technology? Rest assured! AGEDB handles the graph technology plug-in to your existing data model.
If you're interested in learning more about our pluggable graph technology, do not hesitate to contact us through our website or at contact@agedb.io!