
Principle of a Recommendation System using Graph Database
In a world increasingly defined by data and personalization, recommendation systems have emerged as powerful tools that shape our online experiences. These systems, driven by complex algorithms and data analysis, guide our choices, from the movies we watch to the products we buy... But what lies at the core of a recommendation system's success?
Legacy Recommendation Systems
Traditionally, well-known recommendation algorithms suggest content to users based on content, user information, and user content evaluation using a hybrid system that combines collaborative filtering and content-based filtering techniques.

Collaborative filtering
Driven by user data, holds significant potential in guiding product or service purchases, especially as its recommendation accuracy and reliability improve with the growing user base and accumulated data. However, this approach faces challenges when dealing with new users, known as the "cold start" issue, and with larger user populations, resulting in longer recommendation calculations. On the other hand, Content-Based Filtering presents an advantage in that it can make recommendations even with limited user behavior data in the beginning as it allows the analysis of the content itself.
Nonetheless, a recurring challenge in this context is that, due to the constant recommendation of similar products, the variety of items tends to diminish, focusing solely on content characteristics. This limitation hinders the ability to precisely capture the unique preferences of individual users. As the problems surrounding these recommendation algorithms gain prominence, and with the surge in newly generated content and the expanding user base, the market is increasingly calling for a platform or technology that can enhance storage and operational efficiency.
The Graph Recommendation System in Action
To address the aforementioned challenges in recommendation systems, graph data modeling offers a solution. This approach stores user content evaluations in a graph structure and leverages the capabilities of graph algorithms and diverse recommendation techniques to deliver more effective and tailored recommendations. Let's dive in deeper!
There are two major advantages of graph-based recommendation systems compared to legacy recommendation systems that are scalability and diversity of relational modeling.
First, it's important to note that graph-based recommendations distinguish themselves from existing models primarily in their data storage efficiency. Unlike conventional recommendation techniques that rely on sparse matrices to forecast collaborative filtering similarities, the graph-based recommendation system adopts a different approach. It aggregates and retains user content preferences and similarity calculations directly within the graph structure. This allows for the creation and utilization of a graph, focusing on a select number of users with high similarity, using nearest neighbor analysis, and requiring minimal computation. As a result, preference predictions become feasible without the need for comprehensive data utilization.
This unique attribute ensures that the recommendation calculation time does not scale linearly with the increasing number of users or items. The absence of real-time similarity calculations during recommendation service execution prevents a time-expensive process. Furthermore, by exclusively considering preference information in the calculation of item relationships, this approach permits recommendations even in cases of limited user-specific preference data. As a result, it effectively addresses scalability and scarcity issues, mitigating the shortcomings associated with conventional recommendation methods.
The second key advantage of using graph-based recommendation systems is that they help model various data relationships. Recent recommendation systems are gradually developing into super-personalized recommendation systems for individual users. Diversifying recommendation logic or policies mandates the careful curation of data and tailored model training for each user.
Traditional approaches have demanded intricate data selection and complex system modeling for every individual model in pursuit of diversification. The utilization of a graph database, however, simplifies the management of logic and relational models for personalized content recommendations. This approach also enables the modeling of correlations between various content elements. For instance, by representing relationships like 'movie-keyword' or 'movie-actor and director,' a knowledge graph specific to a movie category can be constructed, allowing for the provision of diverse recommendation services to users.
Taking this movie recommendation system into consideration, here are the four processes to follow in crafting an in-depth, yet, structured movie recommendation.
-
Data collection through web scraping
This entails the collection of a wide array of data, including movie details, character profiles, user reviews, ratings, and tags, all of which are essential for powering recommendation services. To facilitate this, a collector is designed to routinely acquire supplementary movie data.
-
Movie knowledge graph modeling and loading
The knowledge graph modeling is intricate and involves the analysis of interconnections among various datasets essential for recommendation services. These diverse movie-related data sources are linked, enabling the provision of a comprehensive service for retrieving diverse movie-related information through the knowledge graph. Moreover, movie data can be associated with films through web scraping (covering new releases, reviews, evaluations, tags, etc.), collected, and then integrated into the knowledge graph for efficient management.
However, it is worth noting that when constructing a knowledge graph by migrating, it is advised to prioritize data mapping, considering the unique value restrictions and data cardinality.
-
Deriving recommendation candidates through a graph recommendation engine
The process of knowledge graph modeling is intricate and involves the analysis of interconnections among various databases essential for recommendation services. These diverse movie-related data sources are linked, enabling the provision of the knowledge graph. Moreover, movie data can be associated with films through web scraping (covering new releases, reviews, evaluations, tags, etc. ), collected, and then integrated into the knowledge graph for efficient management. However, it's worth noting that when constructing a knowledge graph by migrating multiple open databases, particular attention should be given to data mapping, ensuring that unique value restrictions and data cardinality are carefully considered to maintain data integrity.
-
Graph application of similarity-based recommendation
The user's evaluation record, structured as a user-movie graph, lends itself to the application of collaborative filtering recommendations. This method relies on user rating similarity, making it possible to gauge user's preferences. Additionally, employing community detection, a graph-based grouping technique, becomes possible by storing the similarity values between users at the edges of the graph. This facilitates the creation and management of user groups with similar tastes, which can then be harnessed for more targeted and effective recommendations.
-
Graph analysis by connecting movie-related properties in a graph
Another viable technique involves recommending movie characters that align with the user's preferences by employing centrality analysis, such as PageRank. This method is achieved by establishing connections between characters and directors featured in movies through a graph representation. Simultaneously, an array of tags associated with movies is also structured within a graph. Recommendations can then be tailored to users based on their favored tags, enhancing the personalization of the recommendation system.
-
-
Personalized movie recommendations
Among the movie candidates created through the recommendation logic, movies that have already been evaluated individually must be excluded and multiple ratings received between the candidates or Re-Rank must be performed considering the average rating. For each recommendation method, five Re-Rank movies are selected and recommended to the user. At this time, five movies for each recommendation method are connected to the user and stored as a graph. As the recommendation model is updated periodically, it allows the management and real-time provision of five movies for each recommendation method during each update cycle.
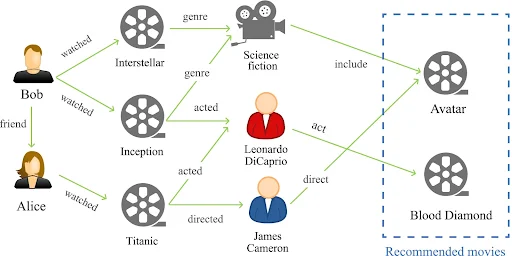
The graph-based recommendation system serves as an ideal knowledge base for systems managing extensive user bases and substantial content volumes, offering maximum effectiveness based on the model operation capabilities of the system operator. Notably, graph data modeling has found application in numerous recommendation systems, including major platforms like Netflix and eBay. The growing body of research on graph distribution storage techniques and advancements in recommendation algorithms underscores the increasing demand for analyzing diverse relational data. This surge in interest highlights the evolving landscape of service systems grounded in such analytical approaches.
Recommendation systems have become integral in shaping our online experiences, guiding our choices in a data-driven and personalized world. With AGEDB's graph data modeling technology combined with PostgreSQL-powered enterprise relational database, these recommendation systems can be efficiently implemented, delivering tailored and effective recommendations to a broad user base. Explore the potential of graph-based recommendations and stay ahead in the era of data-driven personalization with AGEDB. Contact us now for more information.